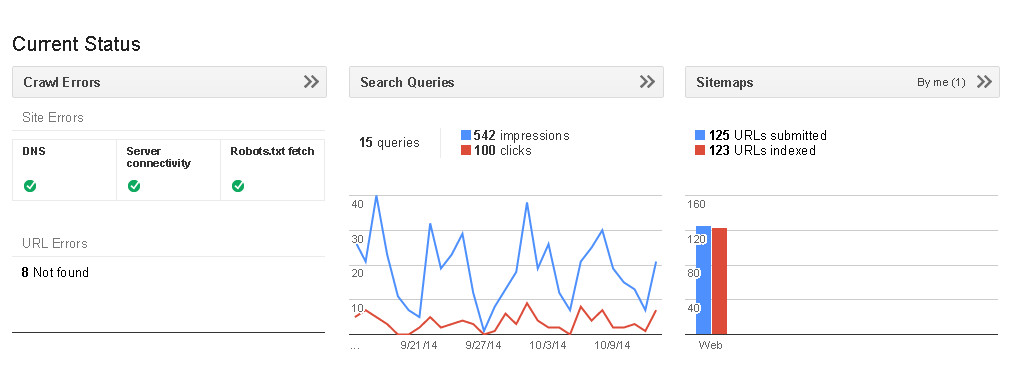
For some time now I have been generating sitemap xml files for google submission using Microsoft Excel. Always knew that there would be a way to generate it on the fly/on request and never bother with that again. But how?
Documentation is not very clear because you need to use multiple programming languages, and also because the whole xml validation process seems very sensitive to errors. Since i am not an experienced programmer, stack exchange became my guide and i have finally managed to do it.
If you have multiple pages, you probably need to create intermediate xmlindex pages. These are basically specially marked index files that point to other index files. Warning: Nested xmlindex files are not allowed by Google (even though are at the end followed and indexed).
<?php Header('Content-type: text/xml');
require_once('../Connections/localhost.php');
if (!function_exists("GetSQLValueString")) {
function GetSQLValueString($theValue, $theType, $theDefinedValue = "", $theNotDefinedValue = "")
{
if (PHP_VERSION < 6) {
$theValue = get_magic_quotes_gpc() ? stripslashes($theValue) : $theValue;
}
$theValue = function_exists("mysql_real_escape_string") ? mysql_real_escape_string($theValue) : mysql_escape_string($theValue);
switch ($theType) {
case "text":
$theValue = ($theValue != "") ? "'" . $theValue . "'" : "NULL";
break;
case "long":
case "int":
$theValue = ($theValue != "") ? intval($theValue) : "NULL";
break;
case "double":
$theValue = ($theValue != "") ? doubleval($theValue) : "NULL";
break;
case "date":
$theValue = ($theValue != "") ? "'" . $theValue . "'" : "NULL";
break;
case "defined":
$theValue = ($theValue != "") ? $theDefinedValue : $theNotDefinedValue;
break;
}
return $theValue;
}
}
mysql_select_db($database_localhost, $localhost);
$query_Recordset1 = "select * from sitemaps where `use`='sitemap'";
$Recordset1 = mysql_query($query_Recordset1, $localhost) or die(mysql_error());
$row_Recordset1 = mysql_fetch_assoc($Recordset1);
$totalRows_Recordset1 = mysql_num_rows($Recordset1);
$xml=new SimpleXMLElement('<?xml version="1.0" encoding="UTF-8" standalone="yes"?>'
.'<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">'
.'</sitemapindex>');
do { $url=$xml->addChild('sitemap');
$website="http://www.tharsitis.gr/".strtolower(str_replace(' ','-',$row_Recordset1['url']));
$url->addChild('loc',$website);
"<br/>";
//$url->addChild('lastmod','XXXXXXXX'); OPTIONAL
} while ($row_Recordset1 = mysql_fetch_assoc($Recordset1));
mysql_free_result($Recordset1);
print($xml->asXML());
?>
This is the xml sitemap index code that worked for me. I created the database recordset using Dreamweaver. It retrieves all the xml index urls from Mysql database.
At the second part of the project i needed to generate the sitemap xml files that the xml index would be point at.
This is the code that worked for me:
<?php Header('Content-type: text/xml');
require_once('../Connections/localhost.php');
if (!function_exists("GetSQLValueString")) {
function GetSQLValueString($theValue, $theType, $theDefinedValue = "", $theNotDefinedValue = "")
{
if (PHP_VERSION < 6) {
$theValue = get_magic_quotes_gpc() ? stripslashes($theValue) : $theValue;
}
$theValue = function_exists("mysql_real_escape_string") ? mysql_real_escape_string($theValue) : mysql_escape_string($theValue);
switch ($theType) {
case "text":
$theValue = ($theValue != "") ? "'" . $theValue . "'" : "NULL";
break;
case "long":
case "int":
$theValue = ($theValue != "") ? intval($theValue) : "NULL";
break;
case "double":
$theValue = ($theValue != "") ? doubleval($theValue) : "NULL";
break;
case "date":
$theValue = ($theValue != "") ? "'" . $theValue . "'" : "NULL";
break;
case "defined":
$theValue = ($theValue != "") ? $theDefinedValue : $theNotDefinedValue;
break;
}
return $theValue;
}
}
$rs1_Recordset1 = "-1";
if (isset($_GET['id'])) {
$rs_Recordset1 = strtolower(str_replace ( '-', ' ',$_GET['id']));
}
mysql_select_db($database_localhost, $localhost);
$query_Recordset1 = sprintf("SELECT packbrand,packsuuid,packcollection,packsname,folder FROM packs where collectionid=%s and visible='1' order by serial asc",GetSQLValueString($rs_Recordset1, "text"));
$Recordset1 = mysql_query($query_Recordset1, $localhost) or die(mysql_error());
$row_Recordset1 = mysql_fetch_assoc($Recordset1);
$totalRows_Recordset1 = mysql_num_rows($Recordset1);
$xml=new SimpleXMLElement('<?xml version="1.0" encoding="UTF-8" standalone="yes"?>'
.'<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">'
.'</urlset>');
do {
$brand=$row_Recordset1['packbrand'];
$collection=$row_Recordset1['packcollection'];
$url=$xml->addChild('url');
// $image="image:image";
$website="http://www.tharsitis.gr/".strtolower(str_replace(' ','-',$brand."/".$collection."/".$row_Recordset1['packsuuid']));
$img="http://www.tharsitis.gr/packagecache/".$row_Recordset1['folder']."/".$row_Recordset1['packsuuid'].".jpg";
$url->addChild('loc',$website);
$url->addChild('priority','0.7');
$image = $url->addChild('image:image', null, 'http://www.google.com/schemas/sitemap-image/1.1');
$image->addChild('image:loc',$img, 'http://www.google.com/schemas/sitemap-image/1.1');
$image->addChild('image:caption',$row_Recordset1['packsname'], 'http://www.google.com/schemas/sitemap-image/1.1');
} while ($row_Recordset1 = mysql_fetch_assoc($Recordset1));
mysql_free_result($Recordset1);
print($xml->asXML());
?>
In both files you can skip the initial part where i build the recordset. This was all done automatically by Dreamweaver. Save the files as php files.
Finally, i needed to modify my .htaccess file so that it translated every php request matching the above files to xml. This is a requirement to get Google validate the files correctly.
Rewriterule ^xmlindex.xml$ /xml/xmlindex.php [L] Rewriterule ^p(.*).xml$ /xml/xmlpacks.php?id=$1 [L]
As you can see in the second line of the below htaccess code, I use url variables to generate dynamic xml sitemaps for different sets of urls. Vuala!



 Doing this was some how tiresome because even though I have automated the scanning and saving, using a Dropbox linked scanner from Epson, the photos must be further processed in order to be up to my standards and get saved to my archive.
Doing this was some how tiresome because even though I have automated the scanning and saving, using a Dropbox linked scanner from Epson, the photos must be further processed in order to be up to my standards and get saved to my archive.